Introducing PhAIL: We Measured How Good Robot AI Actually Is. It's Not.
The best robot AI models can fold laundry, sort objects, and assemble parts – in carefully tuned setups, fine-tuned for each specific task. The results are real and the progress is impressive.
But there's a gap nobody talks about. Existing benchmarks – both real-hardware and simulated – measure success rate on household tasks: folding dishcloths, arranging fruits, tidying up a kitchen. They target the home robot future. We think the traction of physical AI will start somewhere else: commercial and industrial applications where the same operation happens hundreds or thousands of times a day. The industry knows about physical AI and is paying attention – but when operations teams ask "how close are these models to actually working for us?", there's no answer. Nobody measures what matters to them: throughput, reliability, and consistency over hundreds of runs.
We built PhAIL – the Physical AI Leaderboard – to find out. The results are live at phail.ai.
The numbers
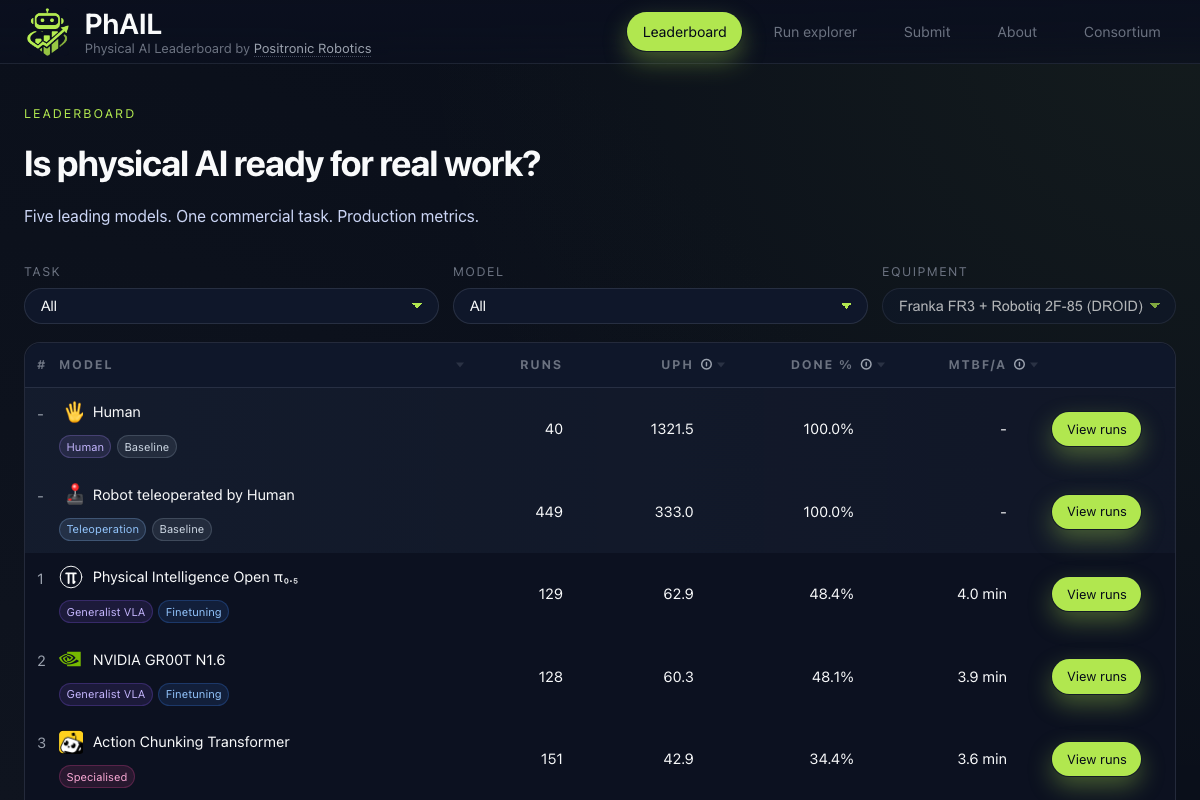
We evaluated four vision-language-action (VLA) models on bin-to-bin order picking: an operator places items in one tote, the robot arm equipped with a gripper picks them one by one and places them into another. Same hardware (Franka FR3 arm with Robotiq 2F-85 gripper), same objects, same conditions. Hundreds of runs per model. Blind evaluation – the operator doesn't know which model is running.
We chose metrics that matter to anyone deciding whether to deploy a robot in production. Units Per Hour (UPH) tells you how fast the robot works – if you're running a fulfilment line, this is the number that determines whether automation pays for itself. Mean Time Between Failures or Assists (MTBF/A) tells you how long the robot runs before a human needs to step in – if it's every few minutes, you haven't saved any labour, you've just added a babysitter.
| UPH | Completion | MTBF/A | |
|---|---|---|---|
| Human (hands) | 1,331 | 100% | – |
| Human (teleoperating the robot) | 330 | 100% | – |
| OpenPI (π0.5) | 64 | 48.5% | 4.0 min |
| GR00T N1.6 (NVIDIA) | 60 | 47.7% | 3.9 min |
| ACT (LeRobot) | 44 | 35.0% | 3.6 min |
| SmolVLA (HuggingFace) | 18 | 10.8% | 2.7 min |
The best AI model runs at 5% of human throughput. In a typical episode with 8 items and a 4-minute time limit, it moves about half of them before time runs out. It needs operator intervention every four minutes.
Three of the four models – OpenPI, GR00T, and SmolVLA – are fine-tuned versions of large pre-trained VLA models. ACT is trained from scratch on our dataset. None of them are close to production-ready on this task.
Why this matters
These aren't bad models. OpenPI and GR00T are publicly available VLA models from Physical Intelligence and NVIDIA. They were fine-tuned on our task-specific dataset using published training recipes. The gap isn't a failure of any single team – it's where the entire field stands today when you measure with production metrics.
There are datasets and simulated benchmarks in robotics. What's been missing is rigorous, independent measurement on real hardware with the metrics that matter for deployment.
How PhAIL works
PhAIL is designed to be obvious. There's no trick.
An operator places items in an outbound tote, sets the item count in the interface, and hits start. The robot arm and gripper run the model autonomously. Each episode has a time limit of 30 seconds per item. When the model finishes – or time runs out – the operator records how many items were successfully moved. If the robot does something unsafe (we've seen it try to place one tote inside another, or push totes off the table), the operator triggers a safety stop. Every run is recorded with synchronized video and robot telemetry, so any result can be independently verified.
Evaluation is blind: model checkpoints are rotated randomly, and the operator does not know which model is running. This eliminates unconscious bias in how episodes are initiated or scored.
We publish the fine-tuning dataset, training scripts, and full methodology in our white paper. The hardware – Franka FR3 arm with Robotiq 2F-85 gripper in the DROID configuration – is widely available and reproducible.
Why bin-to-bin picking?
When we set out to build a benchmark for physical AI, we wanted to measure what matters for industrial deployment. Not a research task designed to stress-test a model's generalization – a real operation that companies actually need automated.
Bin-to-bin order picking is one of the most common tasks in warehousing, fulfilment, and manufacturing. Millions of these operations happen daily. It's the kind of work where automation has clear economic value – and where the gap between "works in a demo" and "works at production scale" is most visible.
This is the first task. PhAIL is designed to grow: more tasks, more hardware configurations, more object categories. Bin-to-bin picking is where we start because it's commercially important, physically straightforward, and exposes exactly the reliability and throughput gaps that matter.
What we observed
Beyond the headline numbers, three patterns stood out.
More data helps – and it's not enough
We evaluate on four object types: wooden spoons, towels, scissors, and batteries. Performance varies dramatically across them – and it tracks almost perfectly with how much training data we collected for each.
| Object | Training duration | Avg completion | Avg UPH |
|---|---|---|---|
| Wooden spoons | 340 min | 50.3% | 71.0 |
| Towels | 178 min | 38.4% | 48.2 |
| Scissors | 160 min | 25.9% | 32.4 |
| Batteries | 134 min | 27.3% | 34.8 |
The correlation between training data volume and model performance is strong (r = 0.96 for UPH). The task with the most demonstrations (wooden spoons, nearly 6 hours of teleoperation data) performs best across every model. The tasks with the least data (batteries and scissors, around 2.5 hours each) perform worst.
But even the best-performing task tops out at 50% completion. These models are both data-hungry and data-starved – and simply collecting more demonstrations may not be enough to close the gap.
Small changes in setup cause large drops in performance
Between evaluation runs, we vary two things: which side of the workspace the outbound tote is placed on, and which side the external camera is mounted on. Same robot, same task, same objects – just a different spatial arrangement.
The models notice. Tote-left is consistently easier than tote-right across all models, likely because tote-right requires a slightly longer reach and a different approach angle, leading to more collisions. But the more interesting finding is about camera placement.
When the external camera is on the same side as the outbound tote, it has a clear view of both totes. When they're on opposite sides, the inbound tote occludes the outbound one from the camera's perspective. GR00T's completion rate drops by 22 percentage points in the occluded configuration – it relies heavily on the external camera and can't compensate with the wrist camera alone. OpenPI handles the occlusion much better, suggesting more robust visual processing.
A human operator wouldn't notice these changes. For current VLA models, they're the difference between half-working and barely working.
What's next
The leaderboard is open. If your model can do better – with your own architecture, your own fine-tuning, or your own data – submit a checkpoint and prove it on the same hardware.
PhAIL launches with one task and four models. More tasks, more hardware, and more models are coming. We're also planning to test generalization to unseen objects – currently all items appear in the training dataset, but real deployments face new objects constantly. The consortium – including Nebius as founding compute partner and Toloka as data partner – is actively welcoming new members.
- Full methodology: white paper
- Live results: phail.ai
- Fine-tuning dataset (352 episodes, 12GB)
- Positronic – the platform powering PhAIL: GitHub
- Submit your model: phail.ai/submit